Group Members:
Kristen Gray
Charity Hancock
Daniel Kason
Kathryn Skutlin
Allison Wyss
The Data Analysis Group of Professor Fraistat’s ENGL 738T seminar set out to use the visualization and analysis tool Woodchipper with the goal of finding patterns among a collection of texts. We chose the “Gothic” genre and further limited the texts to the 18th and 19th centuries—beginning with arguably the first Gothic novel, Horace Walpole’s The Castle of Otranto, and ending with Bram Stoker’s Dracula. The initial thirty Gothic texts chosen consist of some of the most renowned titles in Gothic literature, including The Mysteries of Udolpho by Ann Radcliffe, The Monk by Matthew Gregory Lewis, Frankenstein by Mary Shelley, and works by the Brontë sisters and Edgar Allan Poe. A complete spreadsheet of the texts can be found here. In order to further test our research, outliers were also added. The list of non-Gothic texts included Great Expectations by Charles Dickens, Barchester Towers by Anthony Trollope, Treasure Island by Robert Louis Stevenson, and slave narratives by Mary Prince and Frederick Douglass. The digital versions of the texts were found through Project Gutenberg and Hathi Trust. MITH’s Travis Brown used these texts to generate a list of topic models, shown here.
While Gothic is an established genre, we found “the Gothic” an intriguingly difficult term to define. We agreed that there are similar Gothic traits (horror, the supernatural, mood, etc.), but not all appear in every text. We also found that there was the potential that the genre evolved over time or could be further divided into subsets of the genre. These recognitions led us to several curious research questions: Can we identify through data mining the general Gothic elements? Which texts adhere? Which break away? Why? Do some passages register as “most” or “least” Gothic? Working with students from the University of Virginia, we hoped to answer these questions by generating interesting results. When we met as a group and perused our list of texts, we selected several themes we thought might be promising to investigate using Woodchipper. The topics we decided upon were as follows: chronology, genre deviations, geography/setting, and gender.
One subgroup approached their topic of geography from a more exploratory perspective, applying external constraints to text choices (known setting of novel) while remaining open to the direction Woodchipper’s results would take them. Likewise, another subgroup chose texts based around their overarching topic of chronology and were initially able to accommodate the wide-ranging results they encountered. However, when they began to look for specific deviations from the Gothic genre (the delineation of Science Fiction and Horror), the topics returned by Woodchipper did not always seem relevant to their investigation. The subgroup interested in gender (1) (2), who followed a more categorization-based approach, also experienced the same conundrum. They started out with clear definitions of the male and female Gothic, which they hoped Woodchipper would help them interrogate. While they were able to discern some alignment between the results and their guiding hypothesis (the limiting and faulty perspective of male and female Gothic subgenres), many of the topics that governed the resulting splash patterns, though compelling in and of themselves, did not directly aid their inquiry.
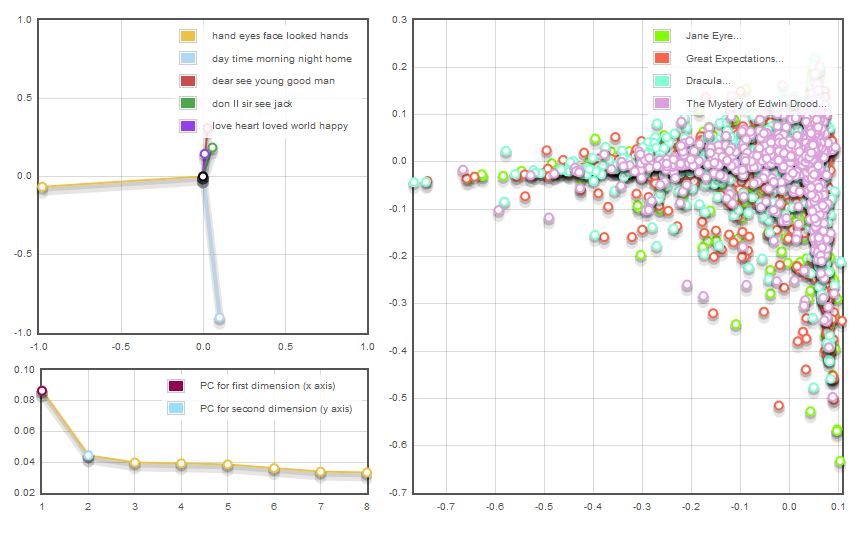
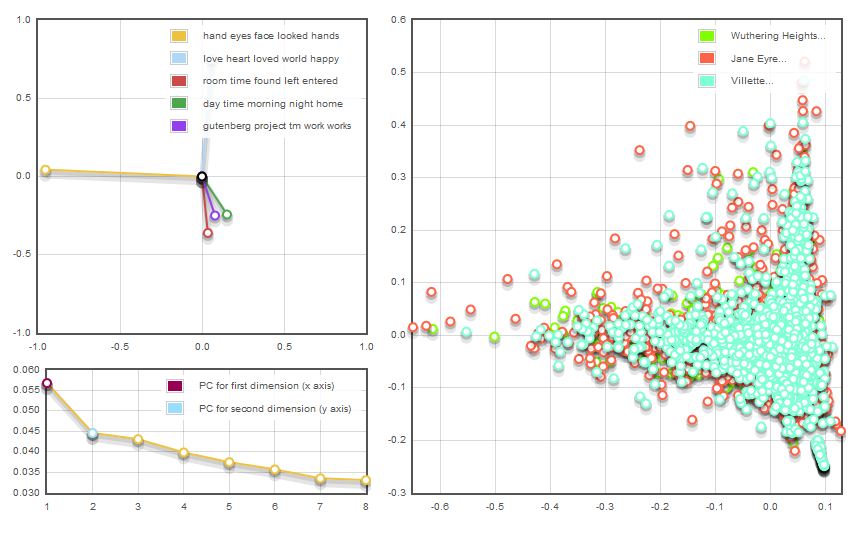
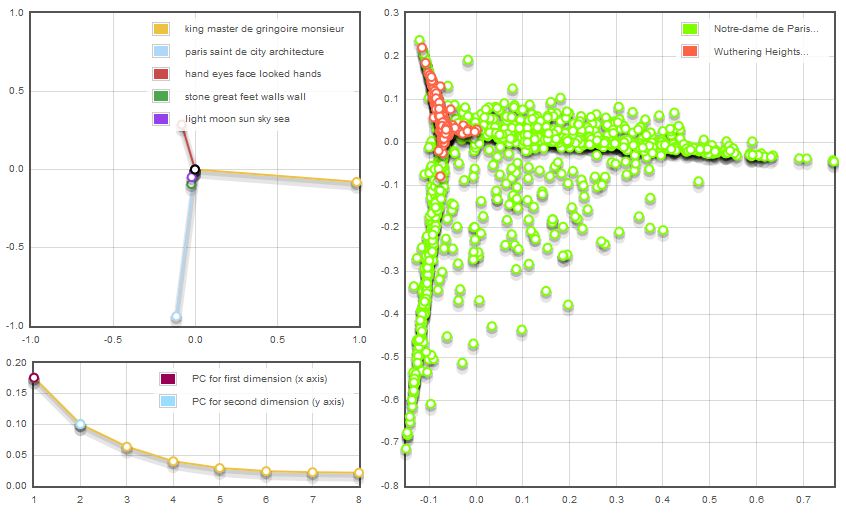
For those groups that ran multiple texts for cross-examination, an additional feature of layering in Woodchipper would have been helpful. When they ran multiple works, there were often disproportionate data point clusters across the texts, which made it impossible to view the data point details on the bottom layers:

With a bit of reconfiguring, they were able to strategically list their texts pre-run so that higher volume works appeared in the bottommost layers; however, they were still unable to access those submerged data points. To reverse the process in order to do so was time-consuming. One group member in particular decided to run two texts separately in order to bypass this issue, though such an approach underutilized Woodchipper’s large-scale text-mining abilities:

We were surprised in our first post-Woodchipper run meeting to find that we were all using such divergent methods, which gave us a range of experiences to discuss. One group member could give advice to another, and each subgroup could return to the project with new ideas for fresh approaches—different combinations of texts to run, different methods for looking at splash patterns, and new ways to understand the topics. After multiple runs, additional texts were added to the original list to further solve (or complicate) our findings.
Though our team included five students studying at UMD and two students from UVA, cross-campus collaboration worked well within the project model we established. With everyone running their own data, then meeting to discuss the findings, there were few scheduling hiccups. Subgroups consisting of two to three members had an easy enough time communicating electronically, rather than face to face. Moreover, it proved fruitful even when a remote group member digressed from the assigned topic, because the resulting analysis was unexpected and showed us the strengths and weakness of yet another way to use Woodchipper.
Labeling topics was a particularly frustrating but ultimately fascinating aspect of the project. Regarding one recurring set in particular (“Felt,” “Made,” “Conduct,” “Received,” “Heart”), each of us offered a varying interpretation in our individual projects. Not surprisingly, our different labels led us to view the category differently and reach alternate interpretations of the data. It was only through collaboration that we became aware of the abundance of differing options and were thus wary of hastily adhering to the first or easiest one.

The biggest challenge was melding our findings into one cohesive conclusion. While each of our individual methodologies matured as a result of discussion, they never merged into one unified method. By the end of the project, we could agree on a very general set of “good idea” practices, but no steadfast rules for processing texts and no overarching procedures for understanding them. Thus, we could compare our results tentatively, perhaps interpretively, but certainly not conclusively. Different ideas went into the chipper in different ways and through different methods—could we be disappointed not to end up with a grand and unifying conclusion about the Gothic novel? Well, yeah, some of us were disappointed.
Ultimately, we decided it was better that way. Instead of conclusions, we found more questions. Each person’s approach led to a different way of seeing the data. The collaborative approach, like Woodchipper, is effective for inspiring new and deeper ways of thinking about literature. However, the individual must be capable of choosing one approach and following it to a conclusive critical end. This parallels all the work we did with Woodchipper. While Woodchipper might be able to more definitively “prove” a trend with a much larger data set, our limited number of texts only allowed it to act as a tool for generating ideas. Interpreting the data, then following it up with old-fashioned textual analysis, falls to the human user.