Editor's note— This is the second post in MITH's series on stewarding digital humanities scholarship.
In September of 2012 MITH moved from its long-time home in the basement of the McKeldin Library on the University of Maryland campus to a newly renovated, and considerably better lit, location next to Library Media Services in the Hornbake Library. If you’ve had a chance to visit MITH’s current location, then you’ve likely noticed its modern, open, and spacious design. And yet, for all its comforts, for all its natural light streaming in from the windows that comprise its northern wall, I still find myself missing our dark corner of the McKeldin basement from time to time: its cubicles, its cramped breakroom, Matthew Kirschenbaum’s cave-like office with frankensteinian hardware filling every square inch, and especially its oddly shaped conference room, packed to the gills and overflowing into the hallway every Tuesday at 12:30 for Digital Dialogues.
In preparation for the move, we delved into those nooks and crannies to inventory the computers and other equipment that had accumulated over the years. MITH is a place that is interested in the materiality of computing—and it shows. Boxes of old media could be found under one cubicle, while a stack of keyboards—whose corresponding computers had long since been recycled—could be found under another. A media cabinet near the entrance contained a variety of game systems from the Preserving Virtual Worlds project, and legacy computer systems, now proudly displayed on MITH’s “spline,” jockied for pride of place on the breakroom table. Tucked away here and there in MITH’s McKeldin offices were a host of retired computer hardware—old enough to have been replaced, but still too modern to merit a listing in MITH’s Vintage Computers collection. Among these systems were two large, black IBM server towers, twice the size and weight of your typical PC. As I lugged them onto the cart in preparation for the move, I couldn’t help but wonder what these servers had been used for, when and why had they been retired, and what data might still be recoverable from them?
A few months ago, I got the chance to find out when I was asked to capture disk images of these servers (a disk image is a sector-by-sector copy of all the data that reside on a storage medium such as a hard disk or CD-ROM). Disk images of these servers would significantly increase access to the data they contained, and also make it possible for MITH to analyze them using the BitCurator suite of digital forensics tools developed by MITH and UNC’s School of Information and Library Science. With BitCurator we would be able to, among other things, identify deleted or hidden files, search the disk images for particular or sensitive information, and generate human and machine-readable reports detailing file types, checksums and file sizes. The tools and capabilities provided by BitCurator offered MITH an opportunity to revisit its legacy web servers and retrospectively consider preservation decisions in a way that was not possible before. However, before we could conduct any such analysis, we first had to be able to access the data on the servers and capture that data in disk image form. It is tackling that specific challenge, accessing and imaging the servers’ hard drives, that I want to focus on in this blog post.
As Trevor described in his recent post on MITH’s digital preservation practices, servers are one important site where complex institutional decisions about digital curation and preservation are played out. As such, I see two communities that have a vested interest in understanding the particular preservation challenges posed by server hardware. First, the digital humanities community where DH centers routinely host their own web content and will need, inevitably, to consider migration and preservation strategies associated with transitioning web infrastructure. These transitions may come in the form of upgrading to newer, more powerful web servers, or migrating from self-hosted servers to cloud-based virtual servers. In either event, what to do with the retired servers remains a critical question. And second, the digital preservation community who may soon see (if they haven’t already) organizations contributing web, email or file servers as important institutional records to be archived along with the contents of their filing cabinets and laptops. Given the needs of these two communities, I hope this blog post will begin a larger conversation about the how and why of web server preservation.
Khelone and Minerva
The two systems represented by those heavy, black IBM towers were a development server named “Khelone” and a production server named “Minerva.” These machines were MITH’s web servers from 2006 to 2009. When they were retired, the websites they hosted were migrated to new, more secure servers. MITH staff (primarily Greg Lord and Doug Reside) developed a transition plan where they evaluated each website on the servers for security and stability and then, based on that analysis, decided how each website should be migrated to the new servers. Some sites could be migrated in their entirety, but a number of websites had security vulnerabilities that dictated only a partial migration. (Later in the summer MITH’s Lead Developer Ed Summers will share a little more about the process of migrating dynamic websites.) After the websites had been migrated to the new servers, Khelone and Minerva, which had been hosted in the campus data center, were collected and returned to MITH. The decision to hold on to these servers showed great foresight and is what allowed me to go back six years after they had been retired and delve into MITH’s digital nooks and crannies.

Imaging and analyzing Khelone and Minerva’s hard drives is a task I eagerly took up because I have been interested in exploring how a digital forensics approach to digital preservation would differ between personal computing hardware (desktop computers, laptops and mobile devices) and server hardware. As I suspected, what I found was that there are both hardware and software differences between the two types of systems, and these differences significantly affect how one might go about preserving a server’s digital contents. In this post I will cover four common features of server hardware that may impede the digital humanities center manager’s or digital archivist’s ability to capture disk images of a server’s hard drives (I will write more about post-imaging BitCurator tools in subsequent posts). Those features are: 1) the use of SCSI hard drives, 2) drive access without login credentials, 3) accessing data on a RAID array, and 4) working with logical volumes. If those terms don’t mean anything to you, fear not! I will do my best to explain each of them and how a digital archivist might need to work with or around them when data held on server hardware.
This topic is necessarily technical, but for those less interested in the technical details than the broader challenge of preserving web server infrastructure, I have included TL;DR (Too Long; Didn’t Read) summaries of each section below.
Server hardware vs. PC hardware
Workflows designed to capture born-digital content on carrier media (hard drives, floppy disk, optical disks, etc.) typically focus on collecting data from personal computing devices. This makes sense both because the majority of carrier media comes from personal computing and also because it fits the familiar framework of collecting the papers of an individual. The presumption in these workflows is that the carrier media can be removed from the computer, connected to a write blocker, and accessed via a digital forensics workstation. (See Marty Gengenbach’s paper “Mapping Digital Forensics Workflows in Collecting Institutions” for example workflows.) Once connected to the workstation, the digital archivist can capture a disk image , scan the contents of the drive for viruses, search for personally identifiable information, generate metadata reports on the drive’s contents, and ultimately transfer the disk image and associated metadata to a digital repository. The challenge posed by server hardware, however, is that if the hard drives are removed from their original hardware environment, they can become unreadable, or the data they contain may only be accessible as raw bitstreams that cannot be reconstructed into coherent files. (I’m using “servers” as a generic term for different server types such as web, email, file, etc.) These factors necessitate a different approach. Specifically, that when archiving born-digital content on server hardware, the safest (and sometimes only) way to access the server’s hard drives is by accessing them while they are still connected to the server.
As a general rule, commercial servers and personal computers use different data bus types (the data bus is the system component that moves data from a disk drive to the CPU for processing). And unfortunately, currently available write blockers and disk enclosures/docking stations do not support the data bus type commonly used in server hardware. Over the years there have been a number of different data bus types. From the late 1980’s to the early 2000’s most desktop systems included hard drives that used a bus type called IDE (Integrated Device Electronics). That bus technology has since given way to Serial ATA (or, SATA), which is found in almost all computers today. However, servers almost always included hard drives that used a SCSI data bus because of SCSI’s higher sustained data throughput. So, while it’s common for a write blocker to have pinout connections for both IDE and SATA (see the WiebeTech ComboDock described in my blog post covering digital forensics hardware), there are none on the market that support any type of SCSI devices (I’d be happily proven wrong if anyone knows of a write blocker that supports SCSI devices). This means that if you want to capture data from a legacy server with SCSI hard drives, instead of removing the drives and connecting them to a digital forensics workstation via a write blocker—as one would do with IDE or SATA hard drives—your best, and maybe only, solution is to leave the drives in the server, boot it up, and capture the data from the running system.
There is an alternative approach that might make sense if you anticipate working with SCSI hard drives regularly. Special expansion cards (called “controller cards”) can be purchased that allow SCSI drives to connect to your typical desktop computer. Adding such a card to your digital curation workstation if, as stated above, you anticipate processing data on SCSI hard drives on a regular basis.
TL;DR #1: Servers almost always use SCSI hard drives, not the more common IDE or SATA drives. Write blockers and disk enclosures/docking stations do not support SCSI drives, so if you want to access the data contained on a server, the best solution is to access them via the server itself.
The LiveCD Approach
How then to best access the data on hard drives still attached to the server? There are two options: The first is simply to boot up the computer, log in, and either capture a disk image or copy over selected files. The second option is what is called a “liveCD” approach. In this case you put the liveCD (or DVD as the case may be) in the drive and have the server boot up off of that disk. The system will boot into a temporary environment where all of the components of the computer are running except the hard drives. In this temporary environment you can capture disk images of the drives or mount the drives in a read-only state for appraisal and analysis.
From a digital forensics perspective, the first option is problematic, bordering on outright negligent. Booting directly from the server’s hard drives means that you will, unavoidably, write data to the drive. This may be something as seemingly innocuous as writing to the boot logs as the system starts up. But what if one of the things you wanted to find out was the last time the server had been up and running as a server? Booting from the server’s hard drive will overwrite the boot logs and replace the date of the last active use with the present date. Further, capturing a disk image from an actively mounted drive means that any running processes may be writing data to the drive during the imaging process, potentially overwriting log files and deleted files.
It may also be impossible to log into the server at all. It is common for servers to employ a “single sign on” technology where the server authenticates a user via an authentication server instead of the local system. This was the case with Khelone and Minerva, making the liveCD approach the only viable course of action.
Booting from a liveCD is a common digital forensics approach because even though the system is up and running, the hard drives are inaccessible—essentially absent from the system unless the examiner actively mounts them in the temporary environment. There a number of Linux based liveCDs, including BitCurator’s, which would have been the ideal liveCD for my needs. Unfortunately, the old MITH servers had CD-ROM, not DVD drives, and the BitCurator liveCD is DVD size at 2.5GB. An additional impediment to using BitCurator is that BitCurator is built on the 64-bit version of Ubuntu Linux, while the Intel Xeon processors in these servers only supported 32-bit operating systems.
With BitCurator unavailable I chose to use Ubuntu Mini Remix, a version of Ubuntu Linux specifically paired down to fit on a CD. Ubuntu has an official minimal liveCD/installation CD but it is a bit too minimal and doesn’t include some necessary features for the disk capture work I needed to do.
TL;DR #2: Use a “liveCD” to gain access to legacy servers. Be careful to note the type of optical media drive (CD or DVD), if the system can boot from a USB drive, and whether or not the server has support for 64 bit operating systems so you can choose a liveCD that will work.
Redundant Array of Inexpensive Disks (RAID)
Once the server is up and running on the liveCD, you may want to either capture a disk image or mount the hard drives (read only, of course) to appraise their content. On personal computing hardware this is fairly straightforward. However, servers have a need for both fault tolerance and speed, which leads most server manufacturers to pair multiple drives together to create what’s called a RAID, or Redundant Array of Inexpensive Disks. There are a number of different RAID types, but for the most part a RAID does one of three things:
- “Stripe” data between two or more disks for increased read/write times (called RAID 0)
- “Mirror” data across two or more disks to build redundancy (called RAID 1, see diagram below)
- Data striping with parity checks to prevent data loss (RAID 2-6)

Regardless of the RAID type, in all cases a RAID makes multiple disks appear to be a single disk. This complicates the work of the digital archivists significantly because when hard drives are configured in a RAID, they may not be able to stand alone as single disk, particularly in the case of RAID 0 where data is striped between the disks in the array.
As with SCSI hard drives, virtually all servers configure their hard drives in a RAID, and the old MITH servers were no exception. It is easy to determine if a server has hard drives configured in a RAID by typing “fdisk -l”, which reads the partition information from each hard drive visible to the operating system. The “fdisk -l” command will print a table that gives details on each drive and partition. Drives that are part of a raid will be labeled “Linux raid autodetect” under the “system” column of the table. What is less apparent is which type of RAID the server is using. To determine the RAID type, you use an application called “mdadm” (Multi Disk Administration), which, once downloaded and installed, revealed that the drives on Khelone and Minerva were configured in a RAID 1 (mirroring). There were four drives on each server, with each drive paired with an identical drive so that if one failed, the other drive would seamlessly kick in and allow the server to continue functioning without any downtime.
Because the drives were mirroring rather than striping data, it was possible to essentially ignore the RAID and capture a disk image of the first of the drives that constitute the array and still have a valid, readable disk image. However, this is only the case when dealing with RAID 1 (mirroring). However, if a server employs a RAID type that stripes data, such as RAID 0, then you must recreate the full raid in order to have access to the data. If you image a drive from a RAID 0, you essentially only get half of the data, resulting in so many meaningless ones and zeros.
TL;DR #3: Servers frequently deploy a redundancy technology called RAID to ensure the seamless rollover from a failed drive to a backup. When creating disk images of server hard drives one must first identify the type of RAID being used and from that information determine whether to capture a disk image of the raw device (the unmounted hard drive), or reassemble the RAID and capture the disk image from the disks running in the RAID.
Logical Volumes
The fourth and final server technology I’ll discuss in this post is what is called a “logical volume.” For simplicity’s sake, I’ll draw a distinction between a “physical volume” and a “logical volume.” A physical volume would be all the space on a single drive; its size (its volume) is limited by its physical capacity. If I connect a physical drive to my computer and format it, its volume would only ever be what its physical capacity allowed. A logical volume, by comparison, has the capacity to span multiple drives to create a single, umbrella-like volume. The volume’s size can now be expanded by adding additional drives to the logical volume (see the diagram below). In practice this means that, like a RAID array, a logical volume allows the user to to connect multiple hard disks to a system but have the operating system treat them as a single drive. This capability allows the user to add space to the logical volume on an as-needed basis, so server administrators create logical volumes on servers where they anticipate the need to add more drive space in the future.
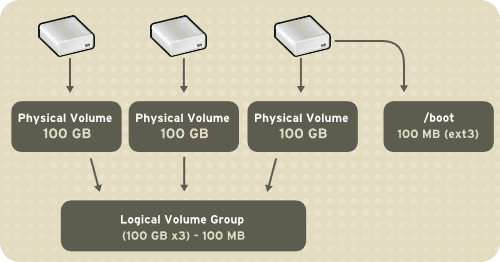
The hard drives on Minerva, the production server, were configured in a logical volume as well as a RAID. This meant that in addition to reconstructing the RAID with mdadm, I had to download a tool called lvm (Linux Volume Manager) to mount the logical volume, which I then used to mount and access the contents of the drives. While I generally advocate the use of disk images for preservation, in this case it may make more sense to capture a logical copy of the data (that is, just the data visible to the operating system and not a complete bitstream). The reason for this is that in order to access the data from a disk image, you must once again use lvm to mount the logical volume. This additional step may be difficult for future users. It is, however, possible to mount a logical volume contained on a disk image in BitCurator, which I’ll detail in a subsequent post.
TL;DR #4: A logical volume is a means of making multiple drives appear to be a single volume. If a server employs a logical volume, digital archivists should take that fact into account when they decide whether to capture a forensic disk image or a logical copy of the data on the drive.
Revisiting Digital MITH
So why go through this? Why heft these old servers out of the storage closet and examine images of systems long-since retired? For me and for MITH it comes down to understanding our digital spaces much like our physical spaces. We have all had that moment when, for whatever reason, we find ourselves digging through boxes for that thing we think we need, only to find that thing we had forgotten about, but in fact need more than whatever it was we started digging for in the first place. So it was with Khelone and Minerva; what began as something of a test platform for BitCurator tools opened up a window to the past, to _digital _MITH circa 2009. And like their physical corollary, Khelone and Minerva were full of nooks and crannies. These servers hosted course pages for classes taught by past and present University of Maryland faculty, the personal websites of MITH staff, and versions of all the websites hosted by MITH in 2009, including those that weren’t able to be migrated to the new servers due to the security concerns mentioned above. In short, these servers were a snapshot of MITH in 2009—the technologies they were using, the fellows they were working with, the projects they were undertaking, and more. In this case the whole was truly greater than the sum of its parts (or the sum of its hosted websites). These servers—now accessible to MITH’s current managers as disk images—are a digital space captured in time that tell us as much about MITH as they do about any of the projects the servers hosted.
Understanding web servers in this way has significant implications for digital humanities centers and how they preserve project websites as well as their own institutional history. An atomized approach to preserving project websites decontextualizes them from the center’s oeuvre. Any effort to capture a representative institutional history must demonstrate the interrelated web of projects that define the center’s scholarship. Elements such as overlaps between participants, technologies that were shared or expanded upon between projects, funder relationships, and project partnerships, to name a few, form a network of relationships that is visible when websites are viewed in their original server context. However, this network becomes harder to see the moment a website is divorced from its server. In MITH's case, examination of these disk images showed the planning and care with which staff had migrated individual digital projects. Nonetheless, having this additional, holistic view of previous systems is a welcome new capability. It is perhaps asking too much of a DH center to spend already limited system administration resources creating, say, biannual disk images of their web servers. However, when those inevitable moments of server migration and transition come about, they can be approached as an opportunity to capture a digital iteration of the center and its work, and in so doing, hold on to that context.
From a digital preservation perspective, I believe that we need to adopt a holistic approach to archiving web servers. When we capture a website, we have a website, and if we capture a bunch of website we have… a bunch of websites, which is fine. But a web server is a different species; it is a digital space that at any given moment can tell us as much about an organization as a visit to their physical location. A disk image of an institution’s web server, then, is more than just a place to put websites—it is a snapshot of the organization’s history that is, in its way, still very much alive.