
Team MARKUP: Encoding Frankenstein for the Shelley-Godwin Archive
Posted by on Thursday, April 26th, 2012 at 12:09 pm This post was collaboratively written by the UMD members of Team MARKUP. Individual credits follow the section titles in parentheses.
This post was collaboratively written by the UMD members of Team MARKUP. Individual credits follow the section titles in parentheses.
Team MARKUP evolved as a group project in Neil Fraistat’s Technoromanticism graduate seminar (English 738T) during the Spring 2012 term at the University of Maryland, augmented by several students in the “sister” course taught by Andrew Stauffer at the University of Virginia. The project involved using git and GitHub to manage a collaborative encoding project, learning TEI and the use of the Oxygen XML editor for markup and validation, and the encoding and quality-control checking of nearly 100 pages of Mary Shelley’s Frankenstein manuscript (each UMD student encoded ten pages, while the UVa students divided a ten-page chunk among themselves). In what follows, Team MARKUP members consider different phases of our project.
Read on, or jump to a section:
Breaking On Through: Fear and Encoding in the Twenty-First Century (LaRonika Thomas)
Coding the Rest of the Pages (Michael Gossett)
Some Specific Issues Encountered during TEI Encoding (Phil Stewart)
Git Going: Decoding the GitHub for Windows Set-up Process (Jen Ausden)
Handling Marginalia (Clifford Hichar)
Quality Control Checking (Amanda Giffi)
Collaboration with UVa (Nigel Lepianka)
Documenting Our Work (Amanda Visconti).
Augmenting the Schema (Amanda Visconti)
Breaking On Through: Fear and Encoding in the Twenty-First Century (LaRonika Thomas)
I hope the reader will forgive this bit of personal confession, but I feel it is important to address my own motivations for choosing to participate in this group project over the other before I enter into a discussion regarding the encoding of my first page.
It is not that I thought the encoding project would be an objectively more difficult task, but I did think it would be a larger challenge for me personally. Encoding scared me. It ventures into that territory of technology where I begin to lose an intuition over the process. I do not naturally understand “what is going on.” I cannot see the forest for the trees. And I am afraid I will break something. Like the entire internet, for instance, in the single push of a button.
So I wanted to face this technophobia head on. I wanted to heed the call of our Digital Humanities boot camp readings and take up the tools that would allow me to look at our texts in a new way, and ask questions we might not have thought to ask before. It is, as the saying goes, easier said than done.
I installed all of the software, set up all the accounts, downloaded all the necessary files, and (with Amanda Visconti’s help) got everything to talk to each other. And then – I had no idea what to do next. I was paralyzed. I was panicked. I did not know how I would every pick up this language of mod tags and zones. Even more than that, I could not even envision the next step. Even the actual manuscript was looking foreign at this point – how can anyone claim it is even possible to turn Shelley’s handwriting into something digital?!
This was, obviously, I major stumbling block in this project for me. I was afraid to begin for fear of failing. Thank goodness for the patience of my more experienced collaborators, who patiently took me by the hand and lead me through each step. We encountered a stumbling block almost right away – I had downloaded the sg-data folder onto my computer early on, but now GitHub could not find it. We quickly realized that this was because I had moved it from its original location after downloading it. I had only done this to keep my desktop organized. See, with one click of a mouse, one moved folder, I had broken my GitHub! Even moving sg-data back to its original location could not make github recognize it. And if I could not get that to happen, I could not push my pages back to the repository on GitHub and share them with the group.
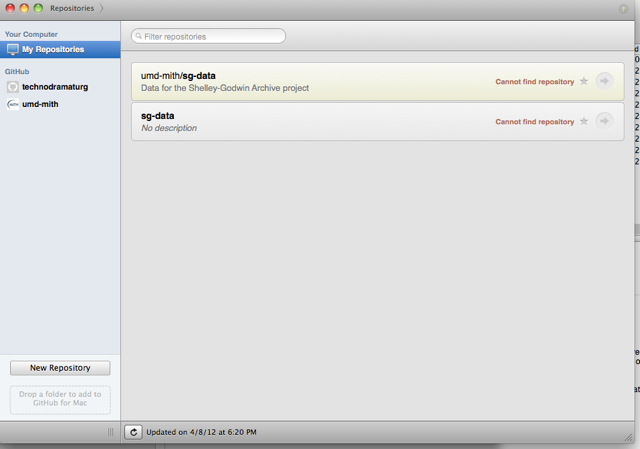
Using the GitHub for Mac application.
Thankfully, we soon discovered a solution (I say we but I really mean Amanda) and I was once again able to link GitHub to the file (by going to Preferences/Repositories/Scan for Repositories in GitHub, and then clicking on the sg-data folder once the scan found it). I could now push my pages back.
In the meantime, I had begun to encode my first page. I think I was very lucky to have claimed the batch of pages I had because most of them were relatively straightforward. The first page, 0062, however, was one of my most complicated. What I realized quickly was that using the transcript of the page could be very helpful. For lines that were clean, you could cut and paste them into Oxygen, so long as you double-checked the work you were doing, and checked the transcript with the manuscript. Once I understood that we were mostly using a few basic tags (ones for delete, add, some Unicode for symbols, etc.) the work began to move more quickly.
One thing I had not realized in my first pass through my pages was that Percy’s edits were in blue on the transcript, so I actually had to go back through all of my pages after I had encoded them and add the notations regarding Percy’s hand. But even that was relatively simple once you understood the proper tags. The language was no longer quite so foreign to me. And since we had our missing repository problem with my sg-data folder, I had not submitted any pages before going back through them to make the Percy adjustments. Perhaps that snag was a blessing in disguise?
If there is a lesson in this, it is that these sorts of projects are possible even for those who do not think of themselves as programmers or handy with a computer beyond its basic uses. I now have some greater understanding of the digital humanities from a hands-on perspective, and it has also changed the way I think about text and manuscript. Now that so many writers use a computer for their writing and edits, we do not have these handwritten documents in abundance. I think though of playwrights in the rehearsal process and the handwritten edits they make to their work while “in the room,” or the stage manager’s prompt book with it’s layers and layers of information. How might these be represented through encoding? What might a large group of these sorts of texts, when encoded, tell us about the process, the actual work and collaboration, that happens during the rehearsal process? I might not ever have asked these questions – at least, not in the same way – if I had not forced my way through my fear of breaking the internet.
Coding the Rest of the Pages (Michael Gossett).
After getting the hang of basic TEI coding during bootcamp and, soon thereafter, going solo with a page at or around Spring Break, the rest of the coding came fairly easy.
One of the most immediate technical challenges, I noticed, was my limited amount of screen space. With needing to hold in place (1) the JPEG of Shelley’s original manuscript page, with its tiny scrawl; (2) Oxygen, to which we were transcribing/coding (Note: More screen space allows you to see more of your coded line at a time, as well as the number of the line you’re on, so as not to lose your place); and (3) the word document of a previous ‘expert’ transcription, to help make out words or determine whether the hand is Percy’s or Mary’s; I can see now how working with a larger screen (I’m dealing with your conventional 13-inch Macbook) or with an external monitor would allow one to spread their work out and see it all simultaneously rather than having to sift through stacked windows or tabs. A ‘minor point,’ in one sense, but a significant one for a long(-er) term project.
As for the coding itself, as I said: once you get the hang of it, things come quickly.
There was some variation among coders re: process, but nothing overly significant. Mine looked something like this:
1. Rough transcription–I copied all the words on the original manuscript page (including strikethroughs, additions, and margin comments) just as words (i.e. not coding) first, pressing ENTER (though not yet coding “lines”) as I went. I consulted the expert transcription after each line to double check accuracy.
2. Rough coding–With the text generally in place, I went through and marked all the most obvious parts of our schema (e.g. lines, placement on the page / zones, page numbers).
NOTE: It was at this point that I (we) realized how vital hot keys would be in moving our work along efficiently. When coding 30-40 lines of text per page from the manuscript, and with each line needing to be noted as such (), being able to highlight passages and tap out the hot key to mark as “line” (or “add” or “del,” later) not only saved time, but also guaranteed validated code by including both the front and the closing tag (e.g. bothand).
3. Fine coding–With the major components in place, this simply became a matter of paying close attention, line by line, to additions, deletions, and modifications of the text. I soon began to sense a sort of ‘modification syntax,’ if you will, that a word or phrase was first marked out and then replaced with another one, or that a word or phrase was added only to be later marked out. Chronology, at times, became important to my coding (particularly when working with other group members, all of whom naturally wanted to be on the same page for the ease of later quality control). This required paying attention to the plot of Frankenstein itself, and using a sort of logic or common sense to figure out the most likely scenario for situations that begged questions like, “Did Mary add this word herself, only to have it marked out by Percy?” or “Did Percy add this suggestion, and then second-guess himself and mark it out?” (NOTE: I made a mild attempt to decipher between hands myself, but always defaulted to the expert transcription on this issue.)
Though these basic additions and deletions marked the most common elements in ‘fine’ coding, we found ourselves addressing several stranger ones, ranging from doodles of flowers in the left-hand margin to Percy and Mary working out math problems on the page (“Were they figuring out the ages of their characters? Or elapsed time in the novel? Or were they simply doing their taxes?” we joked.). We often left the decisions on what to do with these outliers to those ‘higher up,’ those who would better anticipate which information would most likely be useful (or interesting) to the audience that would later take advantage of our work.
The final touches of unicode were then figured in (I say “final touches” because our schema for the unicode was consistently changing, and thus frustrating to those of us who coded early and were asked to constantly reconfigure their ampersands, em-dashes, carets, brackets, etc.).
4. Fine transcription–Ideally, prior to quality control, one would look over the original manuscript again to confirm his own transcription of the text as well as to double check that the confusing parts for which the ‘expert’ transcription had been consulted, matched up. There were very few isolated cases in which one of the group found tiny errors in the ‘expert’ translation, but nonetheless they did exist.
This was also a decent time to consider partially started words or stray marked-out letters for those who may come later and speculate on Mary’s other possible choices/thoughts in writing.
_
Though working with only ten, albeit consecutive, pages didn’t quite give me a good enough sense of Mary’s or Percy’s patterns (e.g. Did Percy cross out “monster” more often to replace it with “creature”? Were Mary’s additions typically reiterations/rephrasings, or pieces of new information? Did Percy’s suggestions tend to stay in the spirit of what Mary had written, or did they go in a new direction? etc.), I would anticipate that a subsequent group conversation and/or a more keenly observed pass through a larger selection of texts could begin to answer some of these bigger, more evocative, questions.
At this point, however, our job–however menial–was the necessary base-level task that would later allow for the more interesting exploration of Frankenstein’s composition to occur.
Some Specific Issues Encountered during TEI Encoding (Phil Stewart).
A variety of issues sprang up for us in the Frankenstein manuscript—some simple, some complex. The more complex ones caused us slow going in the work, mainly from the thought required to work logical issues through, but in part from the time it took to ask and find answers for our questions in the shared Google Doc. Questions posted in the shared document that could not be answered by other coders were passed up to professional staff. In some instances, the schema has not appeared fully able to capture what is going on in the manuscript. Instances like these, generated by novice coders in close contact with the manuscript surrogate images, can inform decisions about how the design of the schema can be adapted. On the encoders’ learning side, direct contact with the manuscript, and with the challenges it presents, has driven incremental improvements in our mastery of the schema. Some difficulties in this learning curve arise because we aren’t versed in the full ecosystem and workflow of TEI, scholarly use cases, etc., yet; we’ve had to ask about the order in which to place our deletion and addition tags, for example (the order is irrelevant, only adjacency counts). Learning markup practices in a real, working case, however, put us in immediate contact with these questions: style, how best to encode so that we captured the desired aspects of what we saw on the page, how to code to capture the logical flow of composition and editing.
The class was able to learn the basics of encoding fairly easily, and was able to apply straightforward markup such as <del>deleted text</del><add>added text</add> immediately. There were more complicated situations, however, due to the dense and complex layers of revisions in some parts of the original manuscript. Slightly more complex tags included those for multi-line additions or deletions (delSpan and addSpan), and the anchor tags used to signal their corresponding endpoints.
More troublesome was the realistic feature of work within a TEI schema under development: We got to see evolutions of the <mod> tag and the reductions of its scope to multi-line additions and those attributed to Percy Shelley (resp=”#pbs” to signal his responsibility). Similarly, the adoption of a conservative approach to attribution led to assignment of responsibility for deletions to be entirely unmarked-up (only additions seen to be in the hand of Percy were marked so; deletions, whatever evidence suggested they were made concurrently with Percy’s work, were left unmarked. This had consequences naturally for the <mod> tag, as noted above: Mod-tagged segments containing paired deletions and additions could not be credited whole to Percy, because we were cautiously leaving deletions unattributed.
One feature appearing to exceed the expressive capabilities of the present schema was an instance of what appears to be a transposition mark, on page 104 (MWS pagination). It appears to reorder a sentence from an awkward configuration to one that almost makes sense—one phrase in between the marks is also moved. The published version of the book that is archived by the Gutenberg Project [get version or don't refer? To which edition does this refer?] solves the incorrect transposition another way, deleting a phrase—but the manuscript appears to show evidence of a minutely different authorial (or editorial, PBS’s) intent than appears in print. Its significance is out of scope of the encoders’ work, but the prospect that it could be invisible to scholars if encoded incorrectly makes it highly desirable to get right, the first time.
The provisional coding solution the group settled on has been to mark two segments of the text as bordered: “<seg rend=”bordered”>enclosed text,</seg>”. For further guidance I have, as instructed in Google Doc follow-up, added a ticket to the markup document, where it resides on the GitHub repository. GitHub directs the question entered in this ticket (a comment on the contents of each of the two encoded lines) to professional staff members.
The schema Encoding Guidelines detail a list transposition marking, “listTranspose,” which appears flexible enough to solve the present problem. As of this write-up, however, I await advice on its applicability.
Another complexity encountered in the course of encoding was the mapping of multiple deletions (and additions, and deletions of the additions) onto a single addition, across lines. Provisionally, the <mod> tag has been used to enclose these, but the question of how the multiple, cascading sets of deletions and additions logically interrelate has proven to be simultaneously engaging and frustrating, at the encoding level. Only a higher-level comprehension of the TEI workflow, and rigorous analysis of the combinational possibilities of the edits where something like this occurs, can guide an encoder, from what I can tell. My encounter with this was fairly simple compared to others’, by their reports.
Git Going: Decoding the GitHub for Windows Set-up Process (Jen Ausden)
Git itself, as defined in the GitBash help prompt, is “a fast, scalable, distributed revision control system.” For a markup project of our scope – one which involves multiple students transcribing multiple pages of Frankenstein via the Shelley-Godwin Archives – the element of “revision control” proved critical.
…at least, this is what I tried to keep in mind during my dive-in to Git: this has to happen. This is necessary. I am man; thou, machine!
As the lone Windows/PC user, unable to utilize the sexy GitHub for Mac interface, “mandatory” became my mantra during what proved to be a series of technological trials and tribulations while establishing the Git framework on my local PC. While proving to be a complex and heavily-end-user-engaged process – at least, for a newbie – properly setting up Git indeed proved critical to the management of our file edits, and the organization of the meta-project.
So, in hopes that my notes may help streamline the Windows set-up process for future users, the essential components of the Git setup process are outlined below (in the context of our markup project purposes):
1) GitHub.com
This is where the games begin, and where I found myself revisiting often to access others’ file changes, view changes to the repository, and perform other repository-related tasks.
Setup Phase One, Step One is to visit GitHub.com and download the Git Setup Wizard, which unpacks both GitBash and GitGUI into a specified folder. Also, you will return here after you generate a new SSH key in GitBash, as follows:
2) GitBash
Git Bash is, well, a Bash prompt – think Windows Command Prompt – with access to Git. It is here that one may run commands to achieve various tasks. Specifically, for Phase One, Step Two, the user will want to get that SSH key generated and copy it in back at GitHub.com. In short, GitHub will “use SSH keys to establish a secure connection between your computer and GitHub,” and this process involves three sub-steps: checking for SSH keys existing, backup and remove any found, and generate a new SSH key. At this point, you enter a pass phrase. Be wiser than I – note this pass phrase.
Phase One, Step Three: Also from GitBash, you will set up your Git username and email.
Once you have your Git username in place, it’s on to Phase Two: Forking, which can be done fairly simply back at Github.com (in short, click the “fork“ button in the repository you wish to access). However, there is a following action, which is to clone this repository locally. Remember, Git is a “revision control system”: therefore the meta-process is 1) clone data so that you can 2) edit select data and then 3) upload changes that will be reviewed before being processed onwards. This was a sobering thought in the midst of command prompts, file paths, keys, and forks: there is a greater purpose here.
So, to clone the repository (rather, to make a local copy of the repository of XML files into which we enter our code, and which the system will push back to the master branch from later), we run a cloning code in GitBash, then one last code (in truncated form, “remote add upstream”, then “git fetch upstream”) that changes your default remote from pointing to “origin” to the original repo(sitory) from which it was forked. And, here is where you will likely need to wield that pass phrase from Phase One, Step Two.
** An Aside: “Cloning” was, in my experience, the most unclear step of the process, so hopefully these notes will help spare another newbie some time. While surely I could have extended my techno-imagination, the lack of feedback from GitBash after running the commands left it an impenetrable mystery as to whether or not the archive had been properly cloned. The work-around, as kindly noted by team leader Amanda Visconti, was to go ahead and start coding in non-cloned (just individual downloads through links in the repository on Github.com) files until project leader Travis could help troubleshoot — then I’d later copy my work into those clones so they could be pushed back to the GitHub.com repository.
Once forked, all the infrastructure is in place for the user to return, or push, all edits into the repository, for team access through Github.com, review and further process.
Where and how to properly access the schema file [containing the coding “rules”] remains a mystery to me: our team leader kindly emailed me the “Relax NG Compact Syntax Schema” file, which had to remain where saved (for me, my Desktop) in order to be recognized by another product, not a part of the Git package: the Oxygen XML Editor.
3) Oxygen XML Editor
Perhaps the most user-friendly of all components, the Oxygen XML Editor is where the PC user can shake off her bewilderment with Git and let the bewilderment with coding content begin! Oxygen allows for multiple XML files to be opened simultaneously as tabs, and if your schema is properly in place, it provides feedback on any exceptions or errors you’ve entered. Just be sure to *save* each file after any changes; moreover, be sure to save in the cloned directory (for example, mine defaulted to “Jennifer Ausden/sg-data/data/engl738t/tei“) not to your desktop, or else GitHub.com won’t know where to look for your changes to the files, and the push process will be doomed. Speaking of uploading doom…
4) GitGUI
GitGUI, while part of the original download bundle, was utilized only when I was struggling to push my Oxygen XML files – at least, those containing any changes since the last push or since the original clone, as the case may be – back to the repo at Github.com.
When I tried running in GitBash the Windows Help Guide’s command “git push origin master”, I was met with the following nerve-shattering error message:
Pushing to git@github.com:umd-mith/sg-data.git
To git@github.com:umd-mith/sg-data.git
! [rejected] master -> master (non-fast-forward)
error: failed to push some refs to ‘git@github.com:umd-mith/sg-data.git’
To prevent you from losing history, non-fast-forward updates were rejected
Merge the remote changes (e.g. ‘git pull’) before pushing again. See the
‘Note about fast-forwards’ section of ‘git push –help’ for details.
“Losing history” being the only information I could decipher, I warily entered the command for ‘git push –help’, whose advice was equally intimidating. In a nutshell: this “fast-forward error” is likely happening because someone else is attempting a simultaneous push. Wait if you can, but if all else fails, go ahead and add “–force” to the end of the code. DO NOT force a push unless you are absolutely sure you know what you’re doing.
Failing to meet that criteria, I had a brief moment of panic, and decided to implement my own local version control: first by attempting to save “my” assigned XML files to a separate folder, until I realized the push could not happen from another folder than the original cloned location, and then by creating other systems (including a highly sophisticated JIC process; that is, emails to myself of the XML files containing my code, “Just In Case”).
Feeling fairly secured against the mysterious inner workings of the software, my test work-around was to switch over from Bash to GUI — which upon opening offers three options: “Create New Repository”, “Clone Existing Repository”, “Open Existing Repository.” In confidence I had probably cloned at this point, I chose to “Open”, successfully “opening” C:/Users/Jennifer Ausden/sg-data/ . This interface was much more friendly; here was a little window of “Unstaged Changes” in the helpful form of a file-path list (for example,“data/engl738t/ox-ms_abinger_c57-0022”) which with simple clicks I could proceed to “Stage,” “Commit,” and finally “Push” back to the master branch and repository.
Heart racing, I flew back to the repository on Github.com, and lo and behold, there at [sg-data / data / eng738t / tei] were all the files (ox-ms_abinger_c57-0022 to ox-ms_abinger_c57-0031) to which I had made (and saved) a code change.
Huzzah! Scores of emails and help searches later, the brave little PC was now equipped with:
1) a secure connection to Github.com
2) a Github.com username and password
3) a “fork” in the repository at Github.com
4) a local, cloned version of the holding-place for all the empty XML files, to be filled with our markup coding magic via Oxygen
5) the Oxygen XML Editor program in which to type up the code for each file
6) a copy of the schema file, so Oxygen could properly “Validate” each file; aka, alert me to any coding incompatible with the schema
7) through Git GUI, a way to push back my changes to the repo on Github.com
And so it appears, Windows users can eventually function in, and contribute to, a team Git project. Just anticipate being, at least at start-up, the old Windows guy in the brown suit.
Handling Marginalia (Clifford Hichar).
One of the more challenging aspects of the encoding project which I encountered in my own sections were sketches and flirtatious comments added to the text by Percy and Mary Shelley. For example, in 0013.xml a small bundle of flowers was sketched into the margin of the text. While not directly pertinent to the text–though entertaining and delightful–the sketches deserved to be properly encoded. To this end, we used the code <figure><desc> with a description of the image properly encoded in a left margin zone. At times, however, it was unclear what the image was of and I found myself forced to rely on the description provided by our transcriber. I was, unfortunately, unable to determine which @type figure to use for the sketches from www.iconclass.org, though I hope in future to get the chance to try this once more.
Further, I encountered an interesting comment by Percy on page 00017.xml of the manuscript. At the end of a passage he added “O you pretty Pecksie!” Clearly not meant to be part of the Frankenstein text (“which at first seemed enigmatic O you pretty Pecksie!” hardly makes a cohesive sentence), it seemed more a flirtatious remark meant for Mary when she read the corrections he had made to the page. As such, I encoded it as an addition to the text in Percy’s hand, though still within the line (neither super-linear or sub-linear). Of our encoding experience I think this and the doodles were some of my favorite discoveries; it made Percy and Mary seem quite human to me.
Quality Control Checking (Amanda Giffi).
Quality control checking was the important next step after individual encoding of each section, and as we went along, we had to revise ideas of how best to go about checking. At the first meeting for our project, we discussed the idea of having a few group members be quality control checkers—they would not be responsible for encoding as many files as the other group members because they would be checking the rest of the files. We decided to all encode our first page and discuss quality control checking afterwards, and realized that it made more sense to for each of us to encode our 10-page sections and then act as quality control checkers for each other. However, in an 8-person group, it would be far too time consuming for each person to check 70 files (excluding their own 10). It made the most sense to break into small groups of 2-3 people who could all meet in person in a two week time period (4/7-4/20) in order to give us enough flexibility to meet, check the files, make changes, and have another week to assemble the final project.
Once our small groups and meeting times were figured out, we decided to nominate 3 of our files—files we had questions about likely because the files were the most difficult to encode and/or files that demonstrated the encoding choices we had made—and email each other indicating which files to look at. When we meet in person, we were able to point out possible issues in the files—for example, that each piece of marginalia needed its own zone—or ask questions—such as, “how do I describe this doodle in the margin?” After meeting in person, we continued to correspond with our small group via email to address any additional questions that arose as we made changes and prepared for our final pushes to GitHub. As the project progressed, we had been extensively asking questions and answering them in our Google document, but it was still important to have two people look over files to catch errors, answer specific questions, and make sure we were all essentially doing the same encoding.
Collaboration with UVa (Nigel Lepianka)
One of the most distinctive aspects of the TEI Encoding project was the massively collaborative nature of the project. Not only were we working with other classmates, but with students from the University of Virginia as well. During the trip to UVA, we were actually able to touch base for the first time in person about how the project was going. Surprisingly, there was little difference in the way the UVA team and the UMD teams were working through their sections of the encoding. Both sides had questions ranging from the basic (what’s going on with the <sic> tag?) to the advanced (can we make a <del span> cross multiple pages?), and there was actually little difference in conversation with the UVA encoders as both groups tossed questions and answers back and forth.
The group from UVA also expressed sincere gratitude for the Google document we had been compiling throughout the project; this was their primary resource for encoding as the difficulties and questions they were encountering up to that point had been addressed by the spreadsheet of questions and answers we created. Because of this, I think, we were very driven to keep the spreadsheet the most up to date, and most active part of our entire team’s communication, more so than even email and class discussion, because of how reliant both the UMD and UVA groups were on the information contained there. In fact, the majority of the time spent with the TEI encoders at UVA was spent reviewing and modifying the Google doc.
Documenting our work (Amanda Visconti).
We used a central GoogleDoc to teach tech skills (e.g. pushing changes to GitHub), handle administrivia (deadlines, email addresses, who was encoding which files), and hold discussion about the encoding process. This last feature evolved into a three-column table that organized encoders’ questions as they arose (with examples where appropriate, and the encoder’s name so we knew who to ask if we had more questions), the team’s immediate feedback (requests for clarification of an issue, reports on how someone had been handling the same problem, and possible solutions), and a final column titled “The Law”, which contained the team’s final verdict on how to address an issue (sometimes supplied by an SGA staff member).
We corresponded one-to-one via email for some specific technical issues as well as to do quality control, but almost everything else about the project was located in the single GoogleDoc. The dynamically updating Table of Contents feature made things a bit easier, but the Doc still became unwieldy given the number of image snippets we’d embedded to teach tech skills and ask questions about specific manuscript issues. To make things simpler, I created a second, streamlined GoogleDoc with just the information needed for doing final quality control.
Finally, I’m working on a public version of our GoogleDoc for use by other new encoders, especially those who work with the Shelley-Godwin Archive in the future. This evolving resource can be viewed at http://amandavisconti.github.com/markup-pedagogy/.
Augmenting the Schema (Amanda Visconti, cross-posted from here).
How would we augment the SGA schema in terms of adding tags? I’ve started to think about ways to encode Frankenstein more deeply; this thinking has taken the form of considering tags that would let me ask questions about the thematics of the manuscript using Python or TextVoyeur(aka Voyant); I’m also interested in markup that deals with the analytical bibliography aspects of the text, but need to spend more time with the rest of the manuscript images before I think about those. So far, I’ve come up with five new thematic tagging areas I might explore:
- Attitudes toward monstrosity: A tag that would identify the constellation of related words (monster, monstrous, monstrosity), any mentions of mythical supernatural creatures, metaphorical references to monstrosity (e.g. “his vampiric behavior sucks the energy out of you”), and reactions/attitudes toward the monstrous (with attributes differentiating responses to confronting monstrosity with positive, negative, and neutral attitudes). I could then track these variables as they appear across the novel and look for patterns (e.g. do we see less metaphorical references to monstrosity once a “real” monster is more prevalent in the plot?).
- Thinking about doodles: We’re currently marking marginalia doodles with <figure> and a <desc> tag describing the drawing. In our section of the manuscript, many (all?) of these doodles are Percy Shelley’s; I’d like to expand this tag to let me identify and sort these doodles by variables such as complexity (how much thought went into them rather than editing the adjacent text?), sense (do they illustrate the adjacent text?), and commentary (as an extension of sense tagging, does a doodle seem ironically comic given the seriousness or tragedy of the adjacent text?). For someone new to studying Percy’s editorial role, such tagging would help me understand both his editing process and his attitude toward Mary’s writing (reverent? patronizing? distracted? meditative?)
- Names, dates, places: These tags would let us create an animated timeline of the novel that shows major characters as they move across a map.
- Anatomy, whole and in part: To quote from an idea raised in an earlier post of mine, I’d add tags that allowed “tracking the incidence of references to different body parts–face, arms, eyes–throughout Frankenstein, and trying to make sense of how these different terms were distributed throughout the novel. In a book concerned with the manufacture of bodies, would a distant reading show us that the placement of references to parts of the body reflected any deeper meanings, e.g. might we see more references to certain areas of the body grouped in areas of the novel with corresponding emphases on the display, observation, and action? A correlation in the frequency and placement of anatomical terms with Frankenstein‘s narrative structure felt unlikely (so unlikely that I haven’t run my test yet, and I’m not saving the idea for a paper!), but if had been lurking in Shelley’s writing choices, TextVoyeur would have made such a technique more visible.”
- Narrative frames: Tags that identified both the specifics of a current frame (who is the speaker, who is their audience, where are they, how removed in time are they from the events they narrate?) and that frame’s relationship to other frames in the novel (should we be thinking of these words as both narrated by Walton and edited by Victor?) would help create a visualization of the novel’s structure.
I expect that playing around with such tags and a distant reading tool would yield even better thinking about encoding methodology than the structural encoding I’ve been working on so far, as the decisions on when to use these tags would be so much more subjective.
You can follow any responses to this entry through the RSS 2.0 You can leave a response, or trackback.
Pingback: “How Can You Love a Work If You Don’t Know It?”: Six Lessons from Team MARKUP | | Maryland Institute for Technology in the HumanitiesMaryland Institute for Technology in the Humanities
Pingback: The Code, the Canonical, the Communist, the Commonplace: - Technoromanticism
Pingback: Encoding/Performance/Archive - Technoromanticism
Pingback: “How Can You Love a Work If You Don’t Know It?”: Six Lessons from Team MARKUP | Maryland Institute for Technology in the Humanities
Pingback: lustra
Pingback: lustra piotrków
Pingback: kabiny prysznicowe piotrków